
引言
传统爬虫主要依赖于预定义规则来提取数据,我们需要使用较多的代码来限制爬取的目标。但是爬虫结合了AI之后,能够以更加智能和高效的方式采集你所需要的任务。在本文中,我们将从零开始,创建一个爬虫,结合AI来爬取你想要的数据。

环境准备
dotenv: 是一个用于Node.js项目的流行库,它允许开发者轻松地加载环境变量到进程环境中。通过 .env 文件来管理配置信息,可以简化不同环境(如开发、测试和生产)之间的配置管理,并有助于保护敏感信息,比如API密钥或数据库连接字符串。
x-crawl: 是一个灵活的 Node.js 多功能爬虫库。灵活的使用方式和众多的功能可以帮助您快速、安全、稳定地爬取页面、接口以及文件。如果想更深一步了解x-crawl可以去查看它的官网x-crawl
两种方法安装:
1.在生成的package.json文件中添加依赖并根据依赖安装,添加依赖后使用npm i:
"dependencies": {
"dotenv": "^16.4.7",
"x-crawl": "^10.0.2"
}
2.直接下载所需要的两个库:
npm i dotenv
npm i x-crawl
版本号
可以看到在第一种方法中,dependencies中每一个库的后面都有一串数字,这是那个库的版本号,如果你没有做过实战项目或是没有工作经历,你可能会忽略这个不起眼的知识点。
版本号由三个数字组成:主版本号 (MAJOR)、次版本号 (MINOR) 和修订号 (PATCH)
主版本号 (MAJOR) :
次版本号 (MINOR) :
修订号 (PATCH) :
代码部分明确目标网站
我们首先要明确要爬取的网站和内容。在本例中,我们爬取豆瓣电影排行榜— 上的内容。
index.mjs 入口文件创建
先在文件夹下创建一个index.mjs文件。注意:要与package.json文件中的main部分一致。这是一个入口文件。
入口文件是应用程序或库的起始点,它定义了代码执行的起点,负责初始化应用、加载必要的依赖和配置,并开始执行核心逻辑。
导入模块包 + 解构
我们在es6中,在.mjs文件中使用import from导入模块包。
// es6 模块化 导包 解构出两个方法
// 解构运算符
// 分行 可读性好
import {
createCrawl, // 返回爬虫实例
createCrawlOpenAI // openai 配置项
} from 'x-crawl';
import dotenv from 'dotenv';
JS中的解构
在 import {createCrawl,createCrawlOpenAI} from ‘x-crawl’;中使用到了解构,它将x-crawl中的createCrawl和createCrawlOpenAI解构出来使用。
解构赋值是JS中一种从数组或对象中提取数据并赋值给变量的语法。能够将对象,数组一次性解构成一批变量。待解构的对象在右边,解构出来的在左边。它使得代码更加简洁和易读,尤其是在处理复杂的数据结构时。使用{ }来解构对象,使用[ ]来解构数组。有时多与…(剩余运算符)相结合解构。
const obj = {
name: "张三",
age: 18,
hobbies: ["下棋", "喝酒", "交友"]
}
let { name , age }=obj // { } 解构对象
let { hobbies }=obj
// 将数组再次解构
let [competition, ...likes] = hobbies // [ ] 解构数组 ... 表示剩余的
console.log(name) // 张三
console.log(age) // 18
console.log(hobbies) // ["下棋", "喝酒", "交友"]
console.log(competition) // 下棋
consolr.log(likes) // ["喝酒", "交友"]
实例化 爬虫应用 和 OpenAI API客户端实例.env文件保护隐私安全
在实例化OpenAI API之前要先将dotenv模块包导入,并在文件夹下创建.env文件。并将.env写入到.gitignore文件中。.gitignore文件中的文件将不会提交到远程库中,这保证了个人的隐私安全。
.env文件内容(我使用了api.302.ai/v1 代理转发地址):
OPENAI_API_KEY= 你自己的密钥
OPENAI_API_BASE_URL=http://api.302.ai/v1
index.mjs:
import dotenv from 'dotenv'; // 在开头导入包
dotenv.config() // 将.env 文件中的内容读取到process.env中
实例化
在这里我们使用到了在之前解构出来的两个方法:createCrawl和createCrawlOpenAI来创建实例。
createCrawl:返回爬虫实例
createCrawlOpenAI:openai 配置项
// 实例化爬虫应用
const crawlApp=createCrawl({
maxRetry:3, // 最多尝试爬取3次
intervalTime:{ max : 2000, min : 1000} // 控制爬取频率 最大最小时间间隔
})
// 实例化OpenAI API客户端实例
const crawlOpenAIApp=createCrawlOpenAI({
clientOptions:{
apiKey: process.env.OPENAI_API_KEY, // 你自己的密钥
baseURL: process.env.OPENAI_API_BASE_URL, // 代理转发地址
},
defaultModel:{
chatModel:'gpt-4-turbo-preview' //使用 gpt-4o
}
})
爬取豆瓣排行榜
下面的代码我将在注释中解释
crawlApp.crawlPage('https://movie.douban.com/chart') // 发送 http 请求(目标网站)
.then(async (res) => { // 等待接收到后
const { page, browser } = res.data; // 解构出 page 和 browser
const targetSelector = '.indent'; // 要爬取的内容在目标网站中的.indent选择器中 需要在目标网站中查看HTML结构
await page.waitForSelector(targetSelector); // 等待目标选择器出现在页面上
const highlyHTML=await page.$eval(
targetSelector, // 选择器
(el)=>el.innerHTML // 解析html
)
// console.log(highlyHTML);
// 设计 prompt 语句 完成需求,可以规定AI返回的格式
const result=await crawlOpenAIApp.parseElements(
highlyHTML,
`
获取图片链接、电影名称、电影评分、电影简介
输出格式为json 数组。
如:
[{
"src": "...",
"title": "...",
"score": "...",
"desc":"..."
}]
`
)
browser.close(); // 关闭浏览器
console.log(result); // 打印结果
// 将结果中的第一个电影的图片保存在指定的文件夹下
// crawlApp.crawlFile({
// targets: result.elements[1].src,
// storeDirs: './upload' // 存储目录为 './upload'
// })
})
部分结果展示
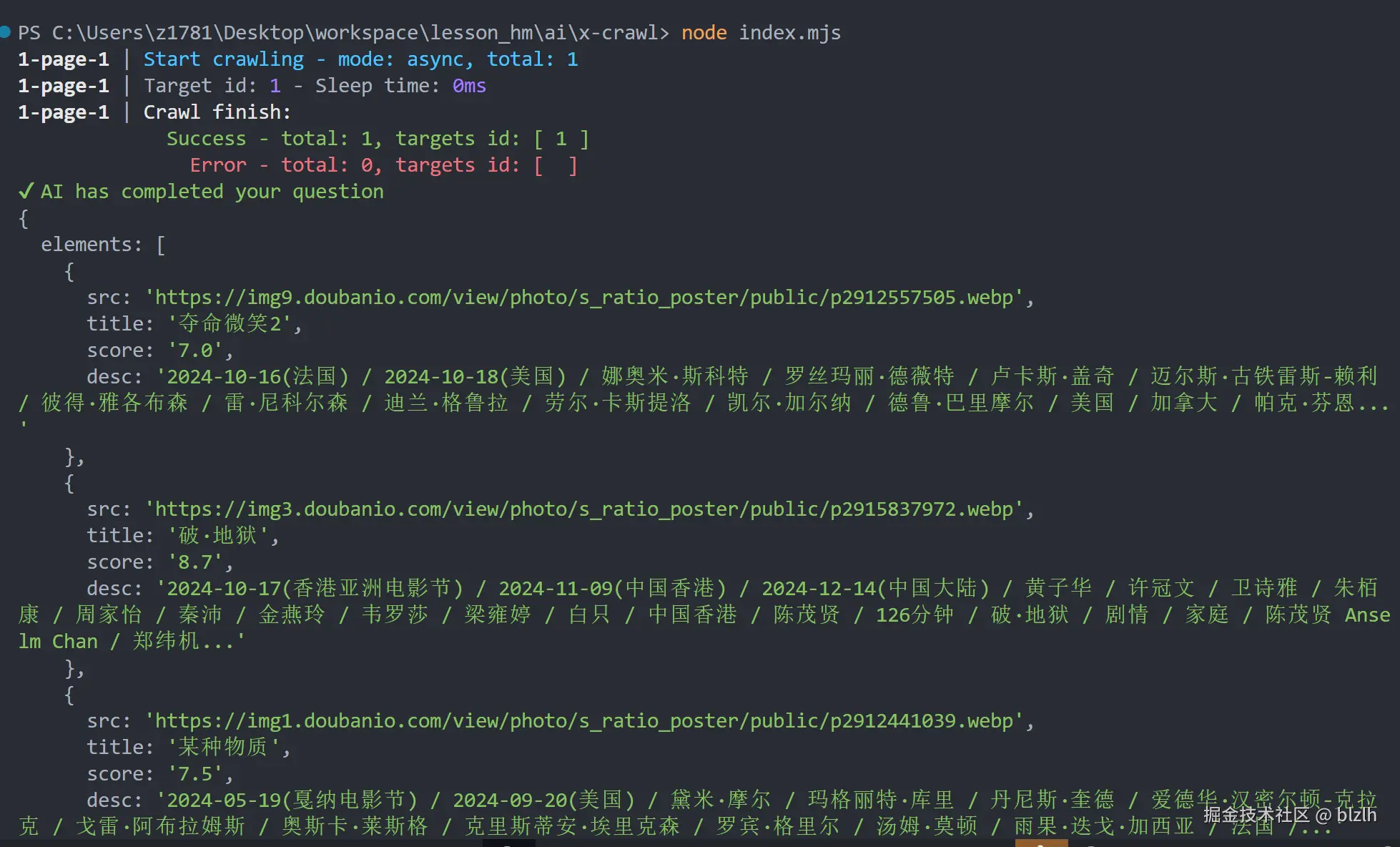
我们通过AI成功爬取了目标网站的所需内容!!!!
结论
AI爬虫结合了传统的网络爬虫技术和先进的机器学习模型,不仅提高了数据抓取的效率和准确性,还使得处理非结构化数据成为可能。通过合理的HTTP请求管理、高效的HTML解析以及智能的大模型应用,开发者能够构建出功能强大且灵活的爬虫系统。