
正则表达式简介
我们如果需要进行文本的复杂处理,就需要正则表达式(Regular Expression)。它描述了一个规则,通过这个规则可以匹配一类字符串。
包:java.lang.util.regex.*
matches()方法是String类的一个方法,用于接收一个正则表达式,并将”本对象”与参数”正则表达式”进行匹配,如果本对象符合正则表达式的规则,则返回true,否则返回false。
//使用正则表达式验证
public class RegexDemo {
public static void main(String[] args) {
System.out.println(checkQQ("09876622")); // false
System.out.println(checkQQ("19876622")); // true
}
private static boolean checkQQ(String qq) {
return qq.matches("[1-9][0-9]{4,}"); // 至少5位数字
}
}
正则表达式语法普通字符
字母、数字、汉字、下划线、以及没有特殊定义的标点符号,都是“普通字符”。表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的一个字符。
转义字符字符含义
n
换行符
t
制表符
^ ,$,.,(, ) , {, } , ? , + , * ,| ,[, ],
匹配斜杠后面的字符本身
标准字符集合
指的是能够与多种字符匹配的表达式。需要注意区分大小写,大写是相反的意思
字符含义
d
任何 数字[0-9] 的简写
D
任何 非数字[^0-9] 的简写
w
任意一个字母或数字或下划线,也就是 A-Z,a-z,0-9,_ 中任意一个。单词字符:[a-zA-Z_0-9] 的简写
W
非单词字符:[^w]
s
包括空格、制表符、换行符等空白字符的其中任意一个。空白字符:[ tnx0Bfr] 的简写
S
非空白字符:[^s]
小数点可以匹配 任意一个字符(除了换行符) 。如果要匹配包括“n”在内的所有字符,一般用 [sS]
自定义字符集合
[ ] 方括号匹配方式,能够 匹配方括号中任意一个字符
字符含义
[ab5@]
匹配 “a” 或 “b” 或 “5” 或 “@” 中的一个
[^abc]
匹配 “a”,”b”,”c” 之外的任意一个字符
[f-k]
匹配 “f”~”k” 之间的任意一个字母
[0-9]
匹配 “0”~”9″ 之间的任意一个数字
[a-zA-Z0-9]
匹配“a-z”或者“A-Z”或者“0-9”之间的任意一个字符
[a-dm-p]
匹配“a 到 d” 或 “m 到 p”之间的任意一个字符
[^A-F0-3]
匹配 “A”-“F”,”0″-“3” 之外的任意一个字符
正则表达式的特殊符号,被包含到中括号中,则失去特殊意义,除了^,-之外
标准字符集合,除小数点外,如果被包含于中括号,自定义字符集合将包含该集合。
比如:[d.-+]将匹配:数字、小数点、-、+
量词
量词(Quantifier),修饰匹配次数的特殊符号
字符含义
匹配表达式 0次或者1次(0、1) ,相当于 {0,1}
表达式 不出现 或出现 任意次(≥0),相当于 {0,}
表达式 至少出现1次(≥1),相当于 {1,}
{n}
表达式重复n次
{n,m}
表达式重复n~m次(包含 n 和 m)
{n,}
表达式至少重复 n 次(包含 n)
匹配次数中的贪婪模式(匹配字符越多越好,默认)
匹配次数中的非贪婪模式(匹配字符越少越好,修饰匹配次数的特殊符号后再加上一个 “?” 号)
字符边界
本组标记匹配的不是字符而是位置,符合某种条件的位置
字符含义
与字符串开始的地方匹配
与字符串结束的地方匹配
b
匹配一个单词边界
b匹配这样一个位置:前面的字符和后面的字符不全是w
匹配模式SINGLELINE:单行模式MULTILINE:多行模式选择符和分组表达式作用
| 分支结构
左右两边表达式之间 “或” 关系,匹配左边或者右边
() 捕获组
(1)在被修饰匹配次数的时候,括号中的表达式可以作为整体被修饰(2)取匹配结果的时候,括号中的表达式匹配到的内容可以被单独得到(3)每一对括号会分配一个编号,使用 () 的捕获根据左括号的顺序从 1开始自动编号。捕获元素编号为零的第一个捕获是由整个正则表达式模式匹配的文本
(?:Expression) 非捕获组
一些表达式中,不得不使用( ),但又不需要保存( )中子表达式匹配的内容,这时可以用非捕获组来抵消使用( )带来的副作用
反向引用(nnn)
分组括号()
String str = "DG8FV-B9TKY-FRT9J-99899-XPQ4G";
//验证这个序列号:分为5组,每组之间使用-隔开,每组由5位A-Z或者0-9的字符组成
String regex = "([A-Z0-9]{5}-){4}[A-Z0-9]{5}";
预搜索(零宽断言)
所以零宽度是对位置的匹配
表达式作用
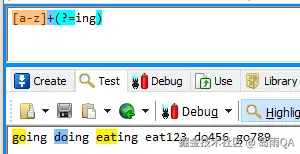
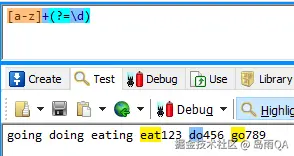
(?=exp)
断言自身出现的位置的后面能匹配表达式exp
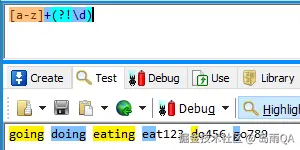
(?!exp)
断言此位置的后面不能匹配表达式exp
(?常用正则表达式功能作用
匹配中文字符
[u4e00-u9fa5]
匹配空白行
ns*r
匹配HTML标记
]*>.*?|
匹配首尾空白字符
^s*|s*$
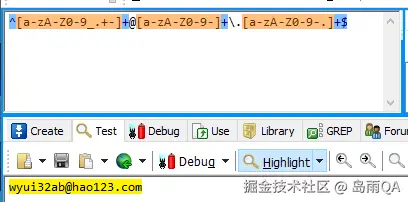
匹配Email地址
w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
匹配网址URL
[a-zA-z]+://[^s]*
匹配国内电话号码
d{3}-d{8}|d{4}-d{7}
匹配腾讯QQ号
[1-9][0-9]{4,}
匹配中国邮政编码
[1-9]d{5}(?!d)
匹配身份证
d{15}|d{18}
匹配ip地址
d+.d+.d+.d+
数据库也可以使用正则表达式,如:
SELECT prod_name FROM products WHERE prod_name REGEXP '.000'
# .匹配任意字符
电话及手机号练习:
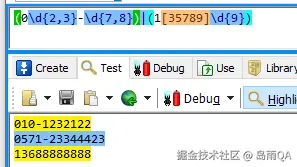
电子邮箱地址练习:
Java中使用正则的方法
split方法使用正则表达式
public String[] split(String regex)
//参数regex就是一个正则表达式。可以将当前字符串中匹配regex正则表达式的符号作为"分隔符"来切割字符串。
String str = "18 4 567 99 56";
String[] strArray = str.split(" +");
replaceAll方法使用正则表达式
public String replaceAll(String regex,String newStr)
//参数regex就是一个正则表达式。可以将当前字符串中匹配regex正则表达式的字符串替换为newStr。
//将下面字符串中的"数字"替换为"*"
String str = "jfdk432jfdk2jk24354j47jk5l31324";
System.out.println(str.replaceAll("d+", "*"));
网络爬虫
public class WebSpider {
public static void main(String[] args) {
List urlList = new ArrayList();
String result = getUrlString("https://music.163.com/");
// 获取所有超链接
// Pattern pattern = Pattern.compile("");
// 获取所有url
Pattern pattern = Pattern.compile("href="(http.+?)"");
Matcher matcher = pattern.matcher(result);
while (matcher.find()) {
urlList.add(matcher.group(1));
}
System.out.println(urlList);
}
public static String getUrlString(String urlStr) {
StringBuilder result = new StringBuilder();
try {
URL url = new URL(urlStr);
BufferedReader reader = new BufferedReader(new InputStreamReader(url.openStream(), "UTF-8"));
String temp = "";
while ((temp = reader.readLine()) != null) {
result.append(temp);
}
} catch (MalformedURLException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}
return result.toString();
}
}